파이썬에서 Selenium 과 BeaultifulSoup4 라이브러리를 이용한 크롤링 방법.
나는 구글맵의 데이터를 크롤링 해보려고 한다.
1. 터미널에 가상환경 생성(Option)
가상환경은 생성하든 안하든 옵션이지만, 혹시나 라이브러리 버전때문에 이상한데 시간을 잡아먹히기 싫어서 왠만하면 설치하는 편.
mac에서는 아래 코드로 생성. -n 뒤에는 가상환경 이름 설정해주는 부분이다. 나는 'project_maps'라고 가상환경 이름을 설정했다.
conda create -n project_maps python=3.6생성 후에는 activate해주기.
conda activate project_maps
2. 라이브러리 다운로드
seolenium 설치
conda install -c conda-forge selenium
chrome driver 설치
chrome driver설치를 해주어야 다음 단계에서 크롬창을 띄우는 명령어가 작동한다.
자신의 크롬 버전에 맞는 걸 아래 사이트에서 설치해주어도 되는것같다. 나는 아래 명령어를 입력했더니 맥에 맞는 크롬드라이버가 저절로 설치되어 사용하였다.
ChromeDriver - WebDriver for Chrome
WebDriver is an open source tool for automated testing of webapps across many browsers. It provides capabilities for navigating to web pages, user input, JavaScript execution, and more. ChromeDriver is a standalone server that implements the W3C WebDriver
sites.google.com
brew install chromedriver
3. 주피터 노트북 코드
먼저 필요한 패키지들을 불러온다
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import pandas as pd
import time크롬창이 띄워지도록 호출한다. 이때, 옵션을 생성한다. 그런데 난 영어로 설정을 했는데 크롬창에 한국어가 표시된다. 왜 그런지 나중에 다시 찾아서 포스팅 예정.
#service = Service(executable_path='/Users/connie/Documents/Python/project_maps')
#driver = webdriver.Chrome(service=service)
#크롬창이 띄워진다
driver = webdriver.Chrome()
# 옵션 생성
options = webdriver.ChromeOptions()
# 옵션 추가
options.add_argument("--lang=en") # 언어변경
options.add_argument('disable-gpu') # GPU를 사용하지 않도록 설정
options.add_argument('headless')크롬창을 최대 크기로 키워주는 명령어와 크롬창에 띄울 url 주소를 입력한다. 나는 구글맵에 해볼 생각이라 구글맵 주소를 입력했다.
driver.maximize_window() # 크롬창 크기 maximize로 조절
driver.get('https://www.google.com/maps/') #띄워진 크롬창에 불러오고 싶은 주소 입력검색하고 싶은 키워드를 입력해준다. 나는 뉴욕 카페를 리스트업 해보고 싶어서 coffee new york으로 키워드를 입력해보았다
# 선택자로 페이지 요소 선택하기(단일)
searchbox = driver.find_element_by_css_selector('input#searchboxinput')
searchbox.send_keys('coffee new york')
searchbutton = driver.find_element_by_css_selector("button#searchbox-searchbutton")
searchbutton.click()
함수로 만들기 전 페이지에서 내가 원하는 자료들의 위치를 찾기 위해서 한 개를 샘플로 추출해보기로 했다. xpath의 위치를 찾는게 좀 노가다였던것 같다. html 관련 지식이 있으면 좀 더 빨리 찾을 수 있을듯싶다.
먼저 검색 키워드 입력 후 노출된 가게들 중 한 개의 가게를 클릭해보았다. 그리고 클릭한 가게의 이름, 주소, 카테고리, 별점, 가격 등의 정보를 수집해보기로 했다.
#첫 번째 리스트의 가게 클릭
driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]/div[3]/div').click()아래 스크린샷을 통해 설명하자면, coffee new york 이라고 검색했을 때 나오는 가게 리스트 중에서 첫 번째 가게 Sweetleaf Coffee&Cocktail Bar를 클릭하도록 명령한 것이다. 클릭하면 오른쪽에 자세한 정보가 노출되는 창이 조그맣게 뜬다. 나는 저 창에서 정보를 수집하고자 했다.
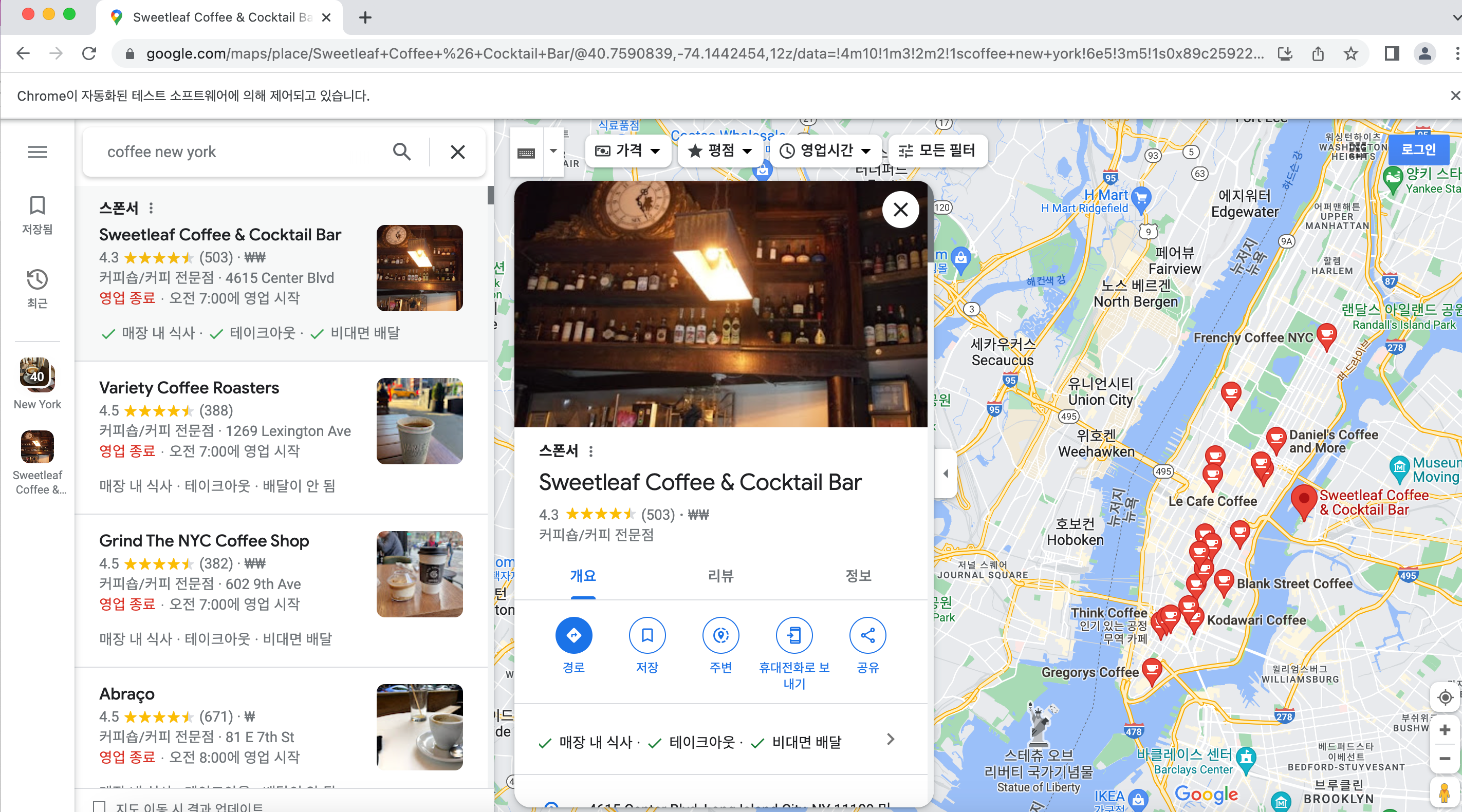
크롬창에서 원하는 위치에 오른쪽 마우스 누르고 '검색'을 입력하면 해당 위치에 대한 html 위치가 표시된다. 이렇게 xpath를 검색했는데, xpath 뒤에 /text() 까지가 복사한 경로였다면 이걸 삭제하고 .text를 입력해서 텍스트가 추출되도록 했다.
title = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[3]/div/div[1]/div/div/div[2]/div[2]/div/div[1]/div[1]/h1').text
address = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[9]/div[3]/button/div/div[3]/div[1]').text
rating = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div/div[1]/div[2]/div/div[1]/div[2]/span[1]/span[1]').text
category = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div/div[1]/div[2]/div/div[2]/span/span/button').text
price = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div/div[1]/div[2]/div/div[1]/span/span/span/span[2]/span/span').text
전부 정상 출력되는걸 확인한뒤 함수를 만들어서 돌리려고 했는데 음식점 리스트가 표출되는 검색창의 스크롤 다운 방법을 몰라서 몇시간을 해맸다. 구글링햇을 때는 body 클래스 전체의 스크롤 내리는 방법이 검색되는데, 구글맵 경우에는 왼쪽 리스트 판넬의 xpath를 찾아서 입력해주어야 한다. 스크롤이 한번만 되면, 스크롤 되는 높이가 길었다가 짧았다가 중구난방으로 출력되서 스크롤 된 리스트가 생성되기 전에 element를 찾을 수 없다는 에러로 for 문이 끝나버린다. 그래서 스크롤 다운을 몇 번 수행하는 함수를 아래처럼 생성한 뒤, 크롤링 함수 안에 넣어주었다. 스크롤 다운 함수 코드는 다음과 같다.
SCROLL_PAUSE_TIME = 2
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
number = 0
while True:
number = number+1
# Scroll down to bottom
scroll = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]')
driver.execute_script('arguments[0].scrollBy(0, 5000);', scroll)
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
print(f'last height: {last_height}')
scroll = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]')
new_height = driver.execute_script("return arguments[0].scrollHeight", scroll)
print(f'new height: {new_height}')
if number == 3:
break
if new_height == last_height:
break
print('cont')
last_height = new_height
이제 검색해서 노출된 가게 리스트들의 정보를 크롤링 하는 함수를 생성한다. 첫 번째 리스트를 클릭해서 가게이름, 주소, 가격 등 세부 정보를 추출한 뒤에 다시 뒤로 돌아가서 두 번째 리스트를 클릭해서 반복하도록 설정했다. 다시 뒤로 돌아가도록 명령하는 코드는 driver.back() 코드이다. for 문을 100까지 반복하도록 설정했지만, 사실 첫 번째 리스트의 xpath가 3부터 시작하고 2단위씩 건어뛰어야 다음 리스트로 넘어가기 때문에 사실상 약 50개정도 리스트업 하도록 실행된 코드이다.
여기서 페이지 스크롤 다운해서 다음 가게의 리스트가 노출되도록 설정하는게 중요.
title_ = []
address_ = []
rating_ = []
category_ = []
price_ = []
for i in range(3, 100, 2):
time.sleep(1)
SCROLL_PAUSE_TIME = 5
global last_height
global new_height
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
number = 0
while True:
number = number+1
# Scroll down to bottom
scroll = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]')
driver.execute_script('arguments[0].scrollBy(0, 1000);', scroll)
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
print(f'last height: {last_height}')
scroll = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]')
new_height = driver.execute_script("return arguments[0].scrollHeight", scroll)
print(f'new height: {new_height}')
if number == i:
break
if new_height == last_height:
break
print('cont')
last_height = new_height
driver.find_element_by_xpath(f'//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[2]/div[1]/div[{i}]/div/a').click()
time.sleep(2)
title = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[3]/div/div[1]/div/div/div[2]/div[2]/div/div[1]/div[1]/h1').text
category = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[3]/div/div[1]/div/div/div[2]/div[2]/div/div[1]/div[2]/div/div[2]/span/span/button').text
try:
address = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[3]/div/div[1]/div/div/div[2]/div[9]/div[3]/button/div/div[3]/div[1]').text
rating = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[3]/div/div[1]/div/div/div[2]/div[2]/div/div[1]/div[2]/div/div[1]/div[2]/span[1]/span[1]').text
price = driver.find_element_by_xpath('//*[@id="QA0Szd"]/div/div/div[1]/div[3]/div/div[1]/div/div/div[2]/div[2]/div/div[1]/div[2]/div/div[1]/span/span/span/span[2]/span/span').text
except:
address = 'na'
rating = 'na'
price = 'na'
title_.append(title)
address_.append(address)
rating_.append(rating)
category_.append(category)
price_.append(price)
driver.back()
print('complete')
각 가게의 정보를 pandas 를 이용해서 데이터프레임으로 생성했다.
import pandas as pd
#pd.set_option('display.max_rows', 100)
data = pd.DataFrame(data=[], columns = ['title', 'address', 'rating', 'category', 'price'])
data['title'] = title_
data['address'] = address_
data['rating'] = rating_
data['category'] = category_
data['price'] = price_
생성된 리스트를 보니 분명 주소, 가격 등 정보가 입력되어 있는데도 추출되지 않은 부분들이 존재한다. 왜인지는 다음에 더 생각해보기로.. 혹시 나처럼 헤매는 사람이 있다면 이 글이 도움되길.
'DS > Python' 카테고리의 다른 글
| [Python] KMeans 사용시 맥북에서 에러 나는 경우 (0) | 2023.06.08 |
|---|---|
| [Python] skimr 대신 skimpy (0) | 2023.06.01 |
| [Python] Flask 사용하기: html 에 github의 py파일 불러올 때 (0) | 2023.05.11 |
| [Python] html file 생성 (0) | 2023.04.28 |
| [Python] class (0) | 2023.02.24 |